") Türkiye (Türkçe)
Türkiye (Türkçe)") Worldwide (English)
Worldwide (English)- Yazma Süresi: 3 Dakika
Overfitting Nedir ?
Overfitting nedir?
Makine öğrenimi alanında sıkça karşılaşılan aşırı öğrenme (overfitting), modelin eğitim verisine gereğinden fazla uyum sağlaması durumudur. Bu yazıda, aşırı öğrenmenin ne olduğunu, nasıl meydana geldiğini ve bu durumu engellemek için kullanılabilecek yöntemleri hızlıca ele alacağız.
Daha iyi anlamak için bu durumu gündelik hayattan bir örnekle açıklayalım. Bir öğrencinin sınav hazırlığını düşünelim. Farz edelim ki, bu öğrenci bir sınava girecek ve öğretmeni ona çalışması için 50 soru veriyor ve öğretmen, sınavda bu 50 soruya benzer sorular soracağını da belirtiyor. Eğer öğrenci sadece bu soruları ezberlemeye odaklanırsa ve konuyu derinlemesine anlamazsa, sınavda karşısına çıkacak diğer 10 farklı soruyu yanıtlamakta zorlanacaktır. Ancak eğer öğrenci, konuyu öğrenmeye ve anlamaya odaklanırsa, ezberlediği sorulardan farklı olsa bile benzer soruları rahatlıkla yanıtlayabilir. Yani overfitting, modelinizin öğrenme yerine ezberlemesine verilen isimdir. Aşırı öğrenmeye uğrayan bir modelde eğitim verileri ile %100'e yakın başarılı sonuç elde edebilirken farklı veriler ile bu oran çok daha düşük olabilmektedir.
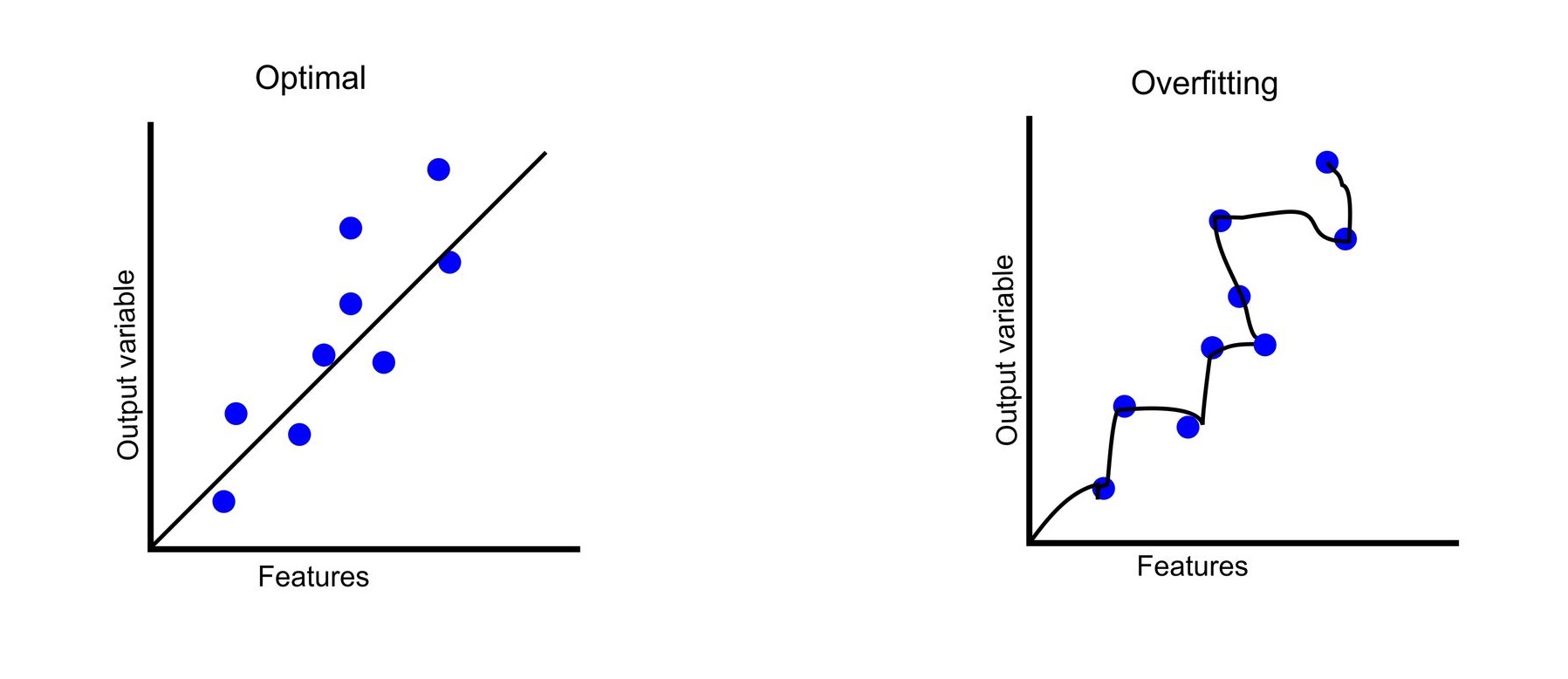
Aşırı öğrenmenin nasıl önüne geçebiliriz?
- Regularization: Bu yöntem, modelin eğitim verisine aşırı uyum sağlamasını engelleyerek, görünmeyen (yeni veya test) verilerdeki performansını artırmayı hedefler. Bu alanda iki ana regularization tekniği bulunmaktadır: L1 ve L2 Regularization.
- Ensembling: Birbirinden ayrı modelleri bir arada kullanmamıza olanak tanıyan bir makine öğrenimi (ML) yöntemidir. Bu yaklaşım, her bir modelin avantajlarından faydalanarak daha karmaşık yapılı örnekler üzerinde çalışabilmemizi sağlar. Bu sayede, modelimiz aşırı öğrenme (overfitting) riskini azaltarak daha iyi genelleştirme yapabilir.
- Daha fazla veri ile eğitim: Aşırı öğrenme sorunu, verilerin çeşitliliğinin yetersiz olmasından kaynaklanıyorsa, veri sayısını artırmak bu duruma çözüm olabilir. Örneğin, bitkilerle ilgili bir çalışma yaptığımızı düşünelim. Eğer kullandığımız çiçek görüntüleri sürekli aynı çiçek cinsine aitse, modelin genelleme yeteneği zayıflayabilir. Farklı çiçek cinslerine ait görüntülerle eğitim yapmak, veri çeşitliliğini artırarak sonuçların daha etkili hale gelmesini sağlar.
- Removing Features: Özellik setimizden alakasız özellikleri çıkararak, hedef değişken ile diğer özellikler arasındaki ilişkileri daha net hale getirebiliriz. Alakasız özellikler, korelasyon matrisi (correlation matrix) kullanılarak belirlenebilir. Bu matris, her özelliğin hedefle olan ilişkisini ve özellikler arasındaki benzerlikleri gösterir. Yüksek korelasyon gösteren özellikler, birbiriyle benzer bilgiler taşıdığı için birinin çıkarılması faydalı olabilir. Ayrıca, hedefle düşük korelasyonu olan özellikler de alakasız sayılabilir ve modelin performansını olumsuz etkileyebilir. Bu sayede daha verimli bir özellik setine ulaşılır ve overfitting riski azaltılmış olur.
- Cross Validation: Modelin genel performansını değerlendirmek için veri setini birden fazla alt kümeye (fold) ayıran bir yöntemdir. Her bir alt küme, modelin eğitim ve test süreçlerinde kullanılır. Bu sayede model daha iyi bir öğrenim süreci geçirir. Bu da overfitting’i azaltmamıza katkı sağlar.
Written by BEYZA KARAŞAHAN
